|
I am a machine learning researcher at Qualcomm AI Research, working on image and video generation with Amirhossein Habibian. I got my Ph.D. at AimageLab, at the University of Modena and Reggio Emilia, where I worked under the supervision of Prof. Rita Cucchiara. Email / CV / Google Scholar / Github |

|
|
My main research interest is currently around generative models for image and video synthesis or editing. I remain curious about developments on open problems I have worked with in the past, such as efficient video processing, out-of-distribution detection and continual learning. A full publication list can be found on my scholar page. |
 |
Kumara Kahatapitiya, Adil Karjauv, Davide Abati, Fatih Porikli, Yuki Asano, Amirhossein Habibian ECCV, 2024 arXiv / project page / bibtex Reducing computational cost of diffusion-based video editing methods by 10x, by squeezing operations on unedited images at the minimum. |
 |
Davide Abati, Haitam Ben Yahia, Markus Nagel, Amirhossein Habibian ICCV, 2023 arXiv / bibtex When processing a video, residuals in frame representations can be processed at a very low integer precision, with very low quantization error. |
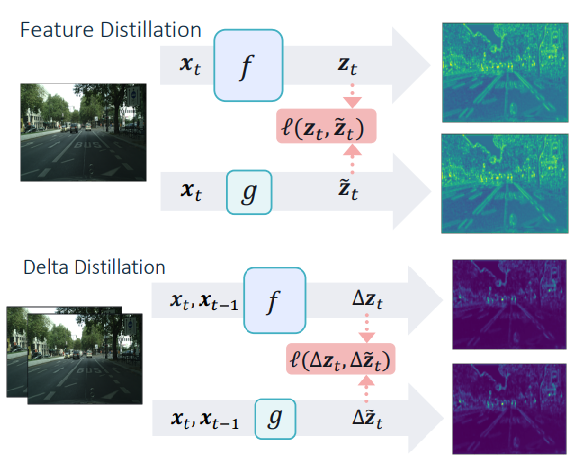 |
Amirhossein Habibian, Haitam Ben Yahia, Davide Abati, Efstratios Gavves, Fatih Porikli ECCV, 2022 arXiv / bibtex / code Instead of distilling neural networks activations, we teach a student network to regress their temporal differences, allowing an improved cost-performance tradeoff. |
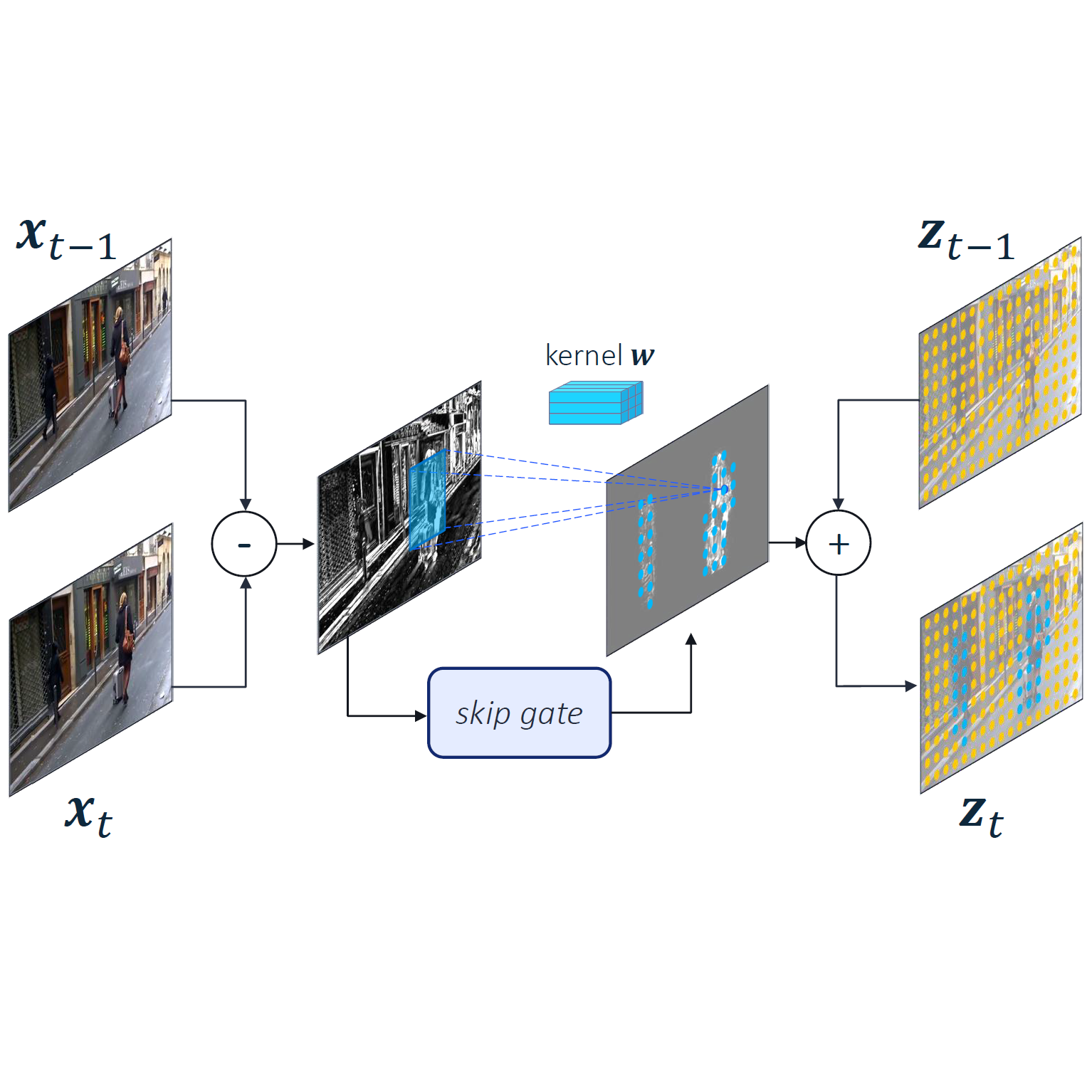 |
Amirhossein Habibian, Davide Abati, Taco Cohen, Babak Ehteshami Bejnordi CVPR, 2021 arXiv / bibtex / code By selectively applying convolutions only on locations that carry meaningful information, the computational cost of neural networks on video can be reduced by 4~5 times. |

 |
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, Simone Calderara NeurIPS, 2020 arXiv / bibtex / code We tackle general continual learning, where an agent is required to learn multiple tasks in a sequence under minimal assumptions about their nature. We run an extensive comparison of many existing methods and introduce a simple model based on knowledge distillation outperforming all of them. |
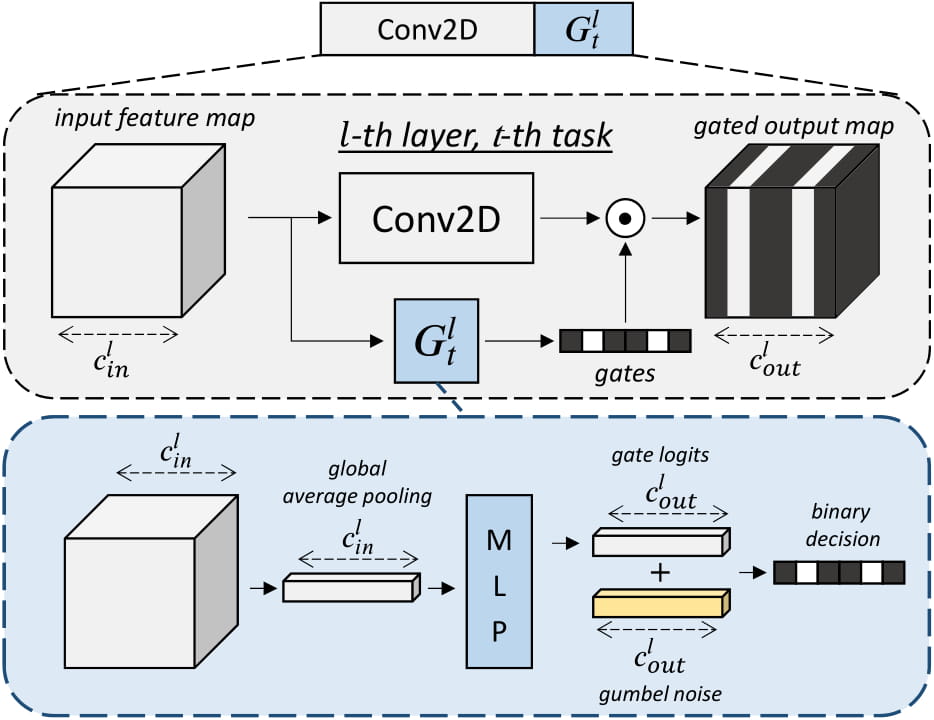 |
Davide Abati, Jakub Tomczak, Tijmen Blankevoort, Simone Calderara, Rita Cucchiara, Babak Ehteshami Bejnordi CVPR, 2020 (Oral presentation) arXiv / bibtex / talk / lecture A continual learning model based on the framework of conditional computation. |
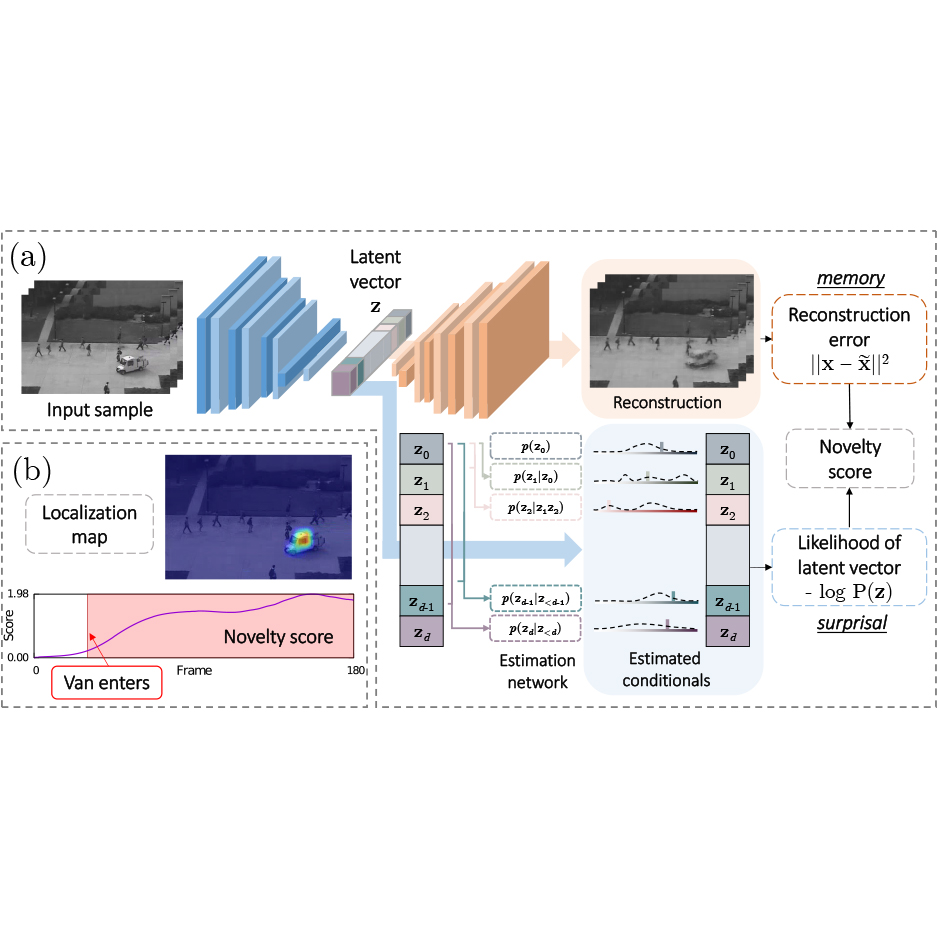 |
Davide Abati, Angelo Porrello, Simone Calderara, Rita Cucchiara CVPR, 2019 arXiv / code / poster / bibtex Applying autoregression in an autoencoder's latent space increases its out-of-distribution detection capabilities. |
 |
Andrea Palazzi, Davide Abati, Francesco Solera, Simone Calderara, Rita Cucchiara IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018 arXiv / dataset / code / video / bibtex We introduce a dataset of human fixations while driving, and a model to predict them given an urban scene. |
|
I regularily serve as a reviewer for the following academic venues. Journals:
Conferences:
|
|
|
|